-
 دیتابیس
دیتابیس
-
 1401-04-26
1401-04-26
-
 601
601
-
 0
0
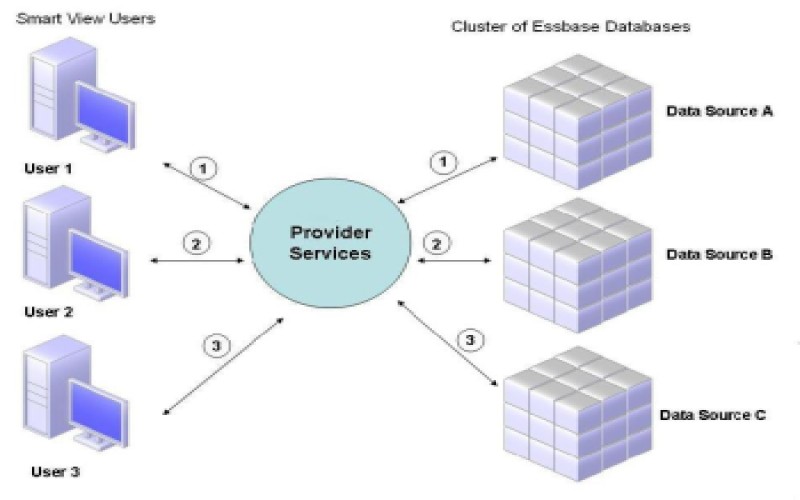
خوشهبندی یا clustering در دیتابیس
خوشهبندی پایگاه داده چیست؟
خوشهبندی پایگاه داده که به آن کلاسترینگ (Clustering) هم گفته میشود، فرآیند ترکیب بیش از یک سرور یا مواردی است که چندین پایگاه داده را به یکدیگر متصل میکند. گاهی ممکن است یک سرور برای مدیریت دادهها و یا تعداد درخواستهایی که به آن ارسال میشود، توان کافی نداشته باشد. هدف خوشهبندی پایگاه داده برطرف کردن این مشکل است. این خوشهبندی با زبان SQL رابطهی نزدیکی دارد. (SQL زبانی است که برای مدیریت اطلاعات پایگاه داده به کار میرود.)
چرا از خوشهبندی استفاده میکنیم؟
خوشهبندی پایگاه داده مواردی چون: افزونگی اطلاعات، بالانس بار، نظارت، اتوماسیون و بسیاری مزایای دیگر را برای سرور فراهم میکند. که همهی این موارد میتوانند کمک شایانی در دسترسی ساده و سریعتر به اطلاعات سرور را فراهم کنند.
افزونگی داده(Data redundancy)
افزونگی داده به تکرار دادههای مشابه، در چندین جدول مختلف در پایگاه داده گفته میشود. فرض کنید یک وبسایت فروشگاهی دارید و در دیتابیس خود برای هر کاربر یک فیلد مشابه با نام آدرس در دو جدول زیر در نظر گرفته شده است:
افزونگی داده به تکرار دادههای مشابه، در چندین جدول مختلف در پایگاه داده گفته میشود. فرض کنید یک وبسایت فروشگاهی دارید و در دیتابیس خود برای هر کاربر یک فیلد مشابه با نام آدرس در دو جدول زیر در نظر گرفته شده است:
جدول اطلاعات شخصی کاربر
جدول اطلاعات هر خرید
وجود فیلد آدرس در دو جدول متفاوت نشاندهندهی افزونگی داده است. افزونگی داده باعث میشود تا برای بهروزرسانی هر فیلد زمان بیشتری صرف کنید. برای مثال در سناریوی بالا باید فرآیند بهروزرسانی فیلد آدرس را در هر دو جدول انجام دهید.
جدول اطلاعات هر خرید
وجود فیلد آدرس در دو جدول متفاوت نشاندهندهی افزونگی داده است. افزونگی داده باعث میشود تا برای بهروزرسانی هر فیلد زمان بیشتری صرف کنید. برای مثال در سناریوی بالا باید فرآیند بهروزرسانی فیلد آدرس را در هر دو جدول انجام دهید.
اما گاهی نیز افزونگی داده یک مزیت محسوب میشود. اگر یک جدول به هر دلیلی دچار مشکل شود و اطلاعات آن از دست برود، اطلاعات جدول دوم قابل استفاده است. در خوشهبندی پایگاه داده چون از چندین سرور برای ذخیرهی دادهها استفاده میشود؛ درصورتی که دادههای یک سرور کامل نباشد، این اطلاعات در سایر سرورها در دسترس است.
متعادلسازی بار ترافیک (Load balancing)
اگر کاربران زیادی به طور همزمان با یک وب سایت یا برنامه تعامل داشته باشند، تعداد درخواستهای انجامشده از سوی آنها ممکن است موجب افزایش بار ترافیکی یک سرور شود. این افزایش بار ترافیکی باعث کند شدن عملیاتهای سرور میشود.
اگر کاربران زیادی به طور همزمان با یک وب سایت یا برنامه تعامل داشته باشند، تعداد درخواستهای انجامشده از سوی آنها ممکن است موجب افزایش بار ترافیکی یک سرور شود. این افزایش بار ترافیکی باعث کند شدن عملیاتهای سرور میشود.
در خوشهبندی پایگاه داده، با تقسیم اطلاعات میان سرورهای مختلف، میتوان کاربران بیشتری را پشتیبانی کرد و هنگامی که یک سرور بار ترافیکی بالایی دارد، سرور دیگری میتواند ترافیک جدید را مدیریت کند. این متعادلسازی ارتباط مستقیمی با قابلیت دسترسی بالا دارد که به عنوان عامل بعدی آن را بررسی میکنیم.
دسترسی بالا(High availability)
بالا بودن میزان دسترسی به یک پایگاه داده، یعنی تعامل برنامه یا وبسایت با پایگاه داده، بدون خطا و در کوتاهترین زمان ممکن انجام شود.
بالا بودن میزان دسترسی به یک پایگاه داده، یعنی تعامل برنامه یا وبسایت با پایگاه داده، بدون خطا و در کوتاهترین زمان ممکن انجام شود.
میزان دسترسی به تعداد تراکنشهای کاربران وابستگی زیادی دارد. هرچه تعداد درخواستها بیشتر باشند؛ بار ترافیکی سرور افزایش پیدا میکند.
با خوشهبندی پایگاه داده و افزایش سرورها، میتوان به سطوح بالایی از دسترسی میان سرورها رسید. افزایش میزان دسترسیپذیری به دلیل متعادلسازی بار ترافیکی ایجاد میشود و چون سرور همواره در دسترس است، پایگاه دادهی آن نیز همواره در تعامل خواهد بود.
نظارت و اتوماسیون(Monitoring and automation)
نظارت و اتوماسیون معمولا به راحتی و با یک نرمافزار انجام میشود. این شیوه برای یک پایگاه دادهی معمولی نیز میتواند استفاده شود، اما هنگامی که دیتابیس را خوشهبندی میکنید، این فرآیند سادهتر خواهد بود. زیرا خوشهبندی امکان خودکار کردن فرآیندهای مختلف در پایگاه داده را فراهم میکند.
نظارت و اتوماسیون معمولا به راحتی و با یک نرمافزار انجام میشود. این شیوه برای یک پایگاه دادهی معمولی نیز میتواند استفاده شود، اما هنگامی که دیتابیس را خوشهبندی میکنید، این فرآیند سادهتر خواهد بود. زیرا خوشهبندی امکان خودکار کردن فرآیندهای مختلف در پایگاه داده را فراهم میکند.
در حالت کلاسترینگ، یک خوشه به عنوان مدیر و ناظر پایگاه داده برای کل دسته انتخاب میشود. این سرور انتخاب شده میتواند به وسیلهی یک کد (scripts) همهی دیتابیسها را به صورت خودکار اداره کند و با همهی آنها رابطه داشته باشد. همچنین اگر به یک سرور بیش از حد درخواست ارسال شود، سرور ناظر هشدار میدهد.
انواع خوشهبندی پایگاه داده یا معماری خوشهبندی
مبحث خوشهبندی پایگاه داده بسیار گسترده است. اینکه خوشهبندی به چه ترتیبی انجام شود و خوشهها بر چه اساسی ساخته شوند به نوع کاربری، حجم اطلاعات موجود در پایگاه داده و اولویتها بستگی دارد و برای هر سیستمی متفاوت است. در این بخش سه روش از معیارهای ساخت خوشهها را بررسی میکنیم:
مبحث خوشهبندی پایگاه داده بسیار گسترده است. اینکه خوشهبندی به چه ترتیبی انجام شود و خوشهها بر چه اساسی ساخته شوند به نوع کاربری، حجم اطلاعات موجود در پایگاه داده و اولویتها بستگی دارد و برای هر سیستمی متفاوت است. در این بخش سه روش از معیارهای ساخت خوشهها را بررسی میکنیم:
خوشههای مبتنی بر دسترسیپذیری(Failover/High availability clusters)
گاهی ممکن است یک سرور اشتباه عمل کند یا متوقف شود. این اتفاق یک چالش بزرگ برای مدیران سیستم است که میتوان با خوشهبندی از بروز این مشکل جلوگیری کرد. خوشههایی که با هدف بهبود دسترسیپذیری ساخته میشوند؛ با افزایش تعداد سرورها و پیکربندی مجدد نرمافزار و سختافزار، میتوانند سیستم را برای هر مشکلی آماده کنند. در این نوع کلاسترینگ، هر سرور، سرور دیگری را کنترل میکند و در صورت عدم موفقیت یک گره، وظایف آن را برعهده میگیرد.
گاهی ممکن است یک سرور اشتباه عمل کند یا متوقف شود. این اتفاق یک چالش بزرگ برای مدیران سیستم است که میتوان با خوشهبندی از بروز این مشکل جلوگیری کرد. خوشههایی که با هدف بهبود دسترسیپذیری ساخته میشوند؛ با افزایش تعداد سرورها و پیکربندی مجدد نرمافزار و سختافزار، میتوانند سیستم را برای هر مشکلی آماده کنند. در این نوع کلاسترینگ، هر سرور، سرور دیگری را کنترل میکند و در صورت عدم موفقیت یک گره، وظایف آن را برعهده میگیرد.
در این خوشهبندی، سیستم باید به اندازهای توانا باشد تا از فعال بودن یا نبودن IP های شبکه باخبر باشد و بداند که هر کدام از سرورها در حال انجام چه عملیاتیهستند. نکتهی مهم این است که سرورها هرگز نباید فعالیتشان را متوقف کنند. این نوع خوشهبندی برای کاربرانی مناسب است که سیستمهایشان باید همواره فعال و در دسترس باشد. مانند: سازمانهای فعال در حوزهی تجارت الکترونیک.
خوشههای مبتنی بر عملکرد(High-Performance Clusters)
در این نوع خوشهبندی، هدف از کلاسترینگ، رسیدن به یک سیستم جامع کامپیوتری با عملکرد بالا است. خوشههای ایجاد شده باید برنامههای پیچیدهای را اجرا کنند که برای محاسبات دقیق مورد نیاز هستند. این محاسبات باید تا حد امکان در زمان کمتری انجام شوند. خوشههای مبتنی بر عملکرد یک عملیات پیچیده را به صورت هوشمندانه بین خود تقسیم میکنند تا حجم کار هر سرور کمتر شود و میزان پردازش بالا رود. این نوع خوشهها معمولا در فعالیتهای علمی استفاده میشوند.
در این نوع خوشهبندی، هدف از کلاسترینگ، رسیدن به یک سیستم جامع کامپیوتری با عملکرد بالا است. خوشههای ایجاد شده باید برنامههای پیچیدهای را اجرا کنند که برای محاسبات دقیق مورد نیاز هستند. این محاسبات باید تا حد امکان در زمان کمتری انجام شوند. خوشههای مبتنی بر عملکرد یک عملیات پیچیده را به صورت هوشمندانه بین خود تقسیم میکنند تا حجم کار هر سرور کمتر شود و میزان پردازش بالا رود. این نوع خوشهها معمولا در فعالیتهای علمی استفاده میشوند.
خوشههای مبتنی بر بار ترافیک(Load Balancing Clusters)
این خوشههای اطلاعاتی برای توزیع بار ترافیکی بین سرورهای مختلف به کار میروند. در این پیادهسازی، سرورها تلاش میکنند تا ظرفیت شبکه را افزایش دهند تا در نهایت عملکرد کل سیستم افزایش یابد. براساس میزان درخواستی که از یک پایگاه داده میشود، ممکن است آن سرور با سرور دیگری ترکیب شود تا این درخواستها بین آنها تقسیم شود. تفاوت این حالت با خوشهبندی مبتنی بر عملکرد این است که سیستم به صورت یکپارچه روی یک عملیات کار نمیکند، بلکه درخواستها را به صورت جداگانه بین سرورهای خود پخش میکند.
این خوشههای اطلاعاتی برای توزیع بار ترافیکی بین سرورهای مختلف به کار میروند. در این پیادهسازی، سرورها تلاش میکنند تا ظرفیت شبکه را افزایش دهند تا در نهایت عملکرد کل سیستم افزایش یابد. براساس میزان درخواستی که از یک پایگاه داده میشود، ممکن است آن سرور با سرور دیگری ترکیب شود تا این درخواستها بین آنها تقسیم شود. تفاوت این حالت با خوشهبندی مبتنی بر عملکرد این است که سیستم به صورت یکپارچه روی یک عملیات کار نمیکند، بلکه درخواستها را به صورت جداگانه بین سرورهای خود پخش میکند.
نویسنده :

- مجید پورداود
- مهندس نرم افزار و تحلیلگر ارشد سیستم های کامپیوتری تحت وب می باشم. از سال 1395 برنامه نویسی را شروع کردم و به زبان های php (فریم ورک laravel -codeigniter) و زبان جاوا اسکریپت (فریم ورک express.js-nest.js) تسلط دارم.
{kind=link}
ثبت دیدگاه جدید
0 دیدگاه
نشانی ایمیل شما منتشر نخواهد شد. بخشهای موردنیاز علامتگذاری شدهاند *